Ellington Kirby

ellingtonkirby31 at gmail.com
Interpreting Interpretability
Recently, the artificial intelligence company Anthropic published a research paper in which they “map the mind” of a large language model (a NYTimes summary of it was written here). There has been a lot of discussion of the paper, a lot of it from a technical level, but also a lot of interest from a non-technical audience. This makes sense, most of us have tried LLM like ChatGPT at this point (if not try Claude out here), and we’ve all heard the statements about the immense impact AI will have on our everyday lives.
The goal of this blog post is to help as general an audience as possible to understand why we call large language models “black boxes”, and why the work Anthropic presented in their paper is particularly interesting. There is no better way to make these systems worthy of trust than making them understood.
Why is “mapping the mind” of a large language model interesting? The image below shows one of the key results of the paper: the authors identified the part of the model that seems to control how emphatically agreeing the model will be in its responses. Controlling this part of the model changes how it behaves, making the model spin an obvious untruth just to praise the human.

This type of result can allow us a much deeper and clearer understanding of the artificial intelligence quickly weaving its way into our everyday lives. This is because these models are more or less “black boxes”, meaning that we don’t have a clear explanation of why the model gives a particular response to any input. We will see why solving this problem is so difficult, and further explore what the Anthropic team were able to uncover.
This post is organized as follows:
- A high level background on neural networks and what makes them a black box.
- Next we introduce the concept of a feature of a language model and why they are useful for interpreting our language models.
- Then come two more in depth sections looking into what makes finding features difficult, and how the authors addressed this problem. These sections are more in depth so skip them if you’re not interested in details.
- Finally we will look at more results like the image above, looking at examples of what the authors were able to accomplish.
The paper from Anthropic published on May 21 2024, is officially titled “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet”.
Wow! There are some big words in there. But moving past the jargon, the title is basically saying: “we built a technique for understanding how LLMs reason, we improve that technique, and we use it to interpret how an LLM used by millions of people understand and generates text”. I hope that by the end of this blog post you have a clearer understanding of what the Anthropic team achieved, and why it is significant, so let’s get started.
Background
The model that was examined in the Anthropic paper is called Claude 3 Sonnet. It is from a family of LLMs produced by Anthropic with a wide variety of impressive capabilities. If you have tried ChatGPT, you can think of Sonnet as better than ChatGPT 3.5 (what was the free version for a long time) but less powerful than the paid version of ChatGPT.
When something is called a “large” language model, it is large in a variety of ways. The model has read millions and millions of pieces of text during its training. The model itself is also “large” in the quantity of numbers inside its brain, called the weights or parameters of the model.
Claude 3 Sonnet and all other LLMs are also neural networks. We can think of a neural network as a pipe having three parts:
- It takes an input. This can be a picture, an audio file, or a piece of text. This goes “into the pipe”.
- It transforms the input into a number, then runs a massive series of simple mathematical operations (things like addition and multiplication) on that number using its the numbers stored in its weights or parameters.
- Finally it finishes that series of mathematical operations, and spits out an output. In the case of an LLM, this is a word, specifically the word that the model predicts will come after the series of text it saw as input.
This repeatable loop is in essence what it means to train a model. In the training process the LLM repeatedly takes a phrase as input and then predicts what it believes the next word in the phrase to be. The numbers inside the model, again the parameters or weights, are then updated very slightly. This update ensures that the model makes the correct prediction more often, steadily learning how to craft intelligent-seeming responses.
The important thing to point out here is that those numbers inside the model are impossible to interpret on their own.
Below is an example (courtest of Tensorflow) of what might be found inside a very small neural network (Claude 3 Sonnet has many millions of times as many parameters). We use these structures because they can be used to perform mathematical operations very quickly and efficiently. But when we have millions of these structures inside the brain of our network, how can we understand what any particular number means?
What does the 0 in the orange part mean? How about the 14 at the end? The specific values of any one part of the model are the result of millions of small mathematical operations, and impossible for a human to just look at and decipher how the LLM is thinking.
This is what researchers, journalists, and engineers mean when they say the model is a “black box”. The interior bits, the brains of the artificial intelligence, aren’t interpretable to us.
When a large language model makes a prediction for the next bit of text, it is the result of a series of mathematical operations using numbers that we can’t explain their origin or significance. They are the numbers the LLM learned in its training that allowed it to best predict the next piece of text, but we don’t have a clear picture of how or why these parameters have any specific value.
The numbers line up really well so that Claude is able to help us translate text and write emails, but we can’t really say why there is a 7 or a 1 or a 3 in any one spot. It’s not magic, more like a chaotic mystery impossible for us to wrap our head around, at least in its current form.
Understanding this black box is then a matter of deciphering this impossibly large puzzle. One approach (pursued by the authors) could be to break the parameters inside the model into pieces, where each piece is responsible for producing a specific kind of text, and understanding these pieces.
The field of research investigating these questions is called “mechanistic interpretability”. Not only are the researchers trying to understand the internal logic behind the output of an LLM, but they are trying to do this in a way that is easily repeatable and “scalable” (i.e. it works on systems of any size).
Understanding this black box is important to see how the model is making its decisions, but it will also be useful in order to take fine grained, purposeful control of the system. If we want the system to behave in a less biased manner, it would be really helpful if we could find where “bias” is stored or represented in the system.
In their paper, the Anthropic team builds upon their previous research in order to transform those very confusing numbers inside an LLM into a series of unique and interpretable concepts that could one day be used to understand the model’s chain of thought, and to offer more specific control over its behavior.
What are Features?
One of the most important concepts from the paper is that the authors were able to identify what they call “features” of the language model.
When we say a person has very “distinguished features”, we mean that they have certain qualities that are unique. We might identify these people by these unique qualities, like their striking eye color, or very large ears. When we say a movie “features” X or Y actor, we mean that they play a character in the movie, often a prominent or defining character.
A feature in a machine learning model then is a unique and measurable property in the data that we identify as significant for learning to complete a particular task. In a classic example we are using a model to predict housing prices. We would input a series of features representing a house into our pipe, and out would pop a predicted price. These features would be things like square footage, neighborhood, or the name of all current ghosts haunting the house. Before we started our real estate prediction project, we have identified these features as important for predicting the value of a house.
In a large language model, all we get is text as input, and produce text as output. We never explicitly select which features the LLM should use. The model needs to learn to make connections between pieces of text itself in the training process in order to best achieve its given goal: predicting the next part of the phrase. And remember, this process is happening on a massive set of numbers inside the model, making it very difficult for a human to look at and understand. Given this predicament, we can’t really locate a specific part of the model that handles any one job, such as generating the word “pancakes”, or refusing to generate text of a violent nature.
The valuable contribution of this paper is to try and map the parts of the brain of the language model to specific and isolated features. Then we can attempt to use these features to understand why the language model responds in a particular way to a given prompt.
For example if we input “I’m so sad…” it would be amazing if we could find a feature in the model representing sadness, then see that it lights up in some way for the next prediction. And then if we could force that part of the model to be lower than normal, maybe it would prevent the model from producing sad text. And maybe forcing it to be higher than normal would make the model behave like a moody teenager.
When I say lights up what I am talking about is called an “activation”. This term is a very important part of the method the authors use to identify features. The activations are the result of the combination of the model’s parameters with a specific piece of text.
As we saw before, the process of training the model involves transforming that text into a number and then performing a series of mathematical operations on it using the numbers stored in the brain of the LLM (the parameters). When a specific piece of text is read by the model, it is combined with the parameters via the aforementioned operations. Some combinations will have a very high value, and others a very negative value, and others a value close to zero.
The parts that have a high value, or high activation, are more responsible for the specific word that is predicted to come next. So when we are looking for features, we want to look for parts of the LLM that consistently have a high activation for the same kind of text. Running many pieces of the text through the model we would start to see patterns and could eventually find parts of the model that react to specific concepts like bias or puns or the word “fauteuil”.
So why haven’t we built a system that can look into the parameters of the model, find the stuff that has a high value for specific text, and call it a day?
Answering this question is a core part of several previous publications from the Anthropic team. A very simple way to answer this question is to say that the LLM learned to re-use parts of its brain for the same features. We can’t easily distinguish why a certain part has a high value for any specific piece of text, because very different pieces of text may cause similar activations.
That gnarly word “polysemanticity” used in the title of their paper refers to this situation: the activations of the model are relevant for many different features. The current state of affairs is that we can’t cleanly separate our features from one another, so we cannot find correlations between features and concepts, much less find features that are directly responsible for producing certain types of text.
This next two section gets a bit deeper into the mathematical details of why polysemanticity is a problem, and how Anthropic resolved it, so if that’s not your vibe feel free to skip ahead. But suffice to say that the authors have developed a solution to this problem, and they are indeed able to identify specific features inside the parameters of the LLM.
Features as Directions
The fundamental problem we have is that our activations do not clearly correspond to identifiable features we could use to interpret our model. Each activation might be caused by multiple overlapping features. The nature of this “overlap” is best explained if we think of our features as “directions”.
Maybe you are thinking of directions like: “Take a left at the stop sign and drive 5 blocks” or “Open the pod bay doors HAL!”.
Instead we mean directions like an arrow pointing to an arbitrary location on a grid. If that arrow points towards the 12 on a clock, we might call that direction North.
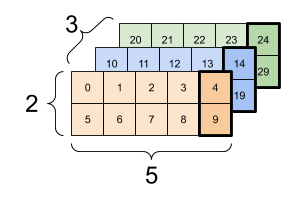
If we think in two dimensions (like a graph with an x and y axis) we can see that any point on our two dimensional grid forms a direction. We just have to draw a line from the origin and finish with a little triangular hat (the triangular hat is actually not necessary; the neural network would need a very large hat rack to store all of them).
We see an example of two directions (often called vectors) below.
Imagine then that we input our text into our neural network. It is transformed into a number, and then transformed by a bunch of math operations. This combination of our input text and our parameters produces our activations.
We then look at our activations. It would be nice if our activation was just a single number, but usually our activations are a long list of numbers, organized and sub organized into lists. We can think of the smallest groups of our activations as directions.
If these smallest groups were two numbers, we would have a direction in a space of two dimensions. If they were three numbers, it would be a direction in a three dimensional space.
Inside a neural network these lists are often much larger. We use these long lists to give the neural network a lot of “space” to learn in.
So when we are looking for features via their activations, we are looking for groups of numbers that we can describe as directions, each pointing to a specific location in the space the neural network works in. We say that one direction has a higher value than another when it is further from the origin point of the grid. In the end, a certain final direction has the highest value over all the other ones, and is responsible for the final prediction.
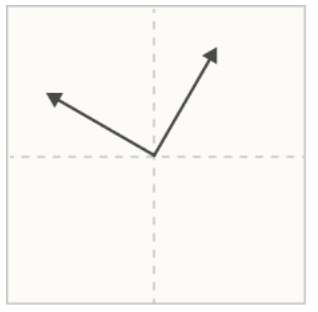
The issue we have is that there are many different ways this final direction could be produced by our neural network.
In the image above we have our output line in yellow. But actually due to the mathematical properties of our directions, we can’t tell why our yellow line is our output. Is it because our single black line had a really high activation? Or is it because the two blue lines each had a high activation, and they interfere with one another?
This is where the authors introduce the fun term of “superposition” Really what they mean is that directions are learned by the neural network and used to make predictions are so dense and high in information that we can’t cleanly separate one from another. We see an overlap in directions where they are used to represent multiple features. This makes interpreting and understanding these models very difficult.
In a previous work the authors fully demonstrated that these properties (superposition and polysemanticity) are a real problem, using like science and stuff. Thankfully, they also introduced a solution to this problem.
Sparse Autoencoders and Scaling Problems
If you start to read Artificial Intelligence research, a few concepts appear all over the place. One of these concepts is the “Autoencoder”.
An autoencoder has many similarities to compression, where information is removed on one end and then re-added on the other, in order to reduce the size of the data being transmitted.
An autoencoder is very similar. It has two parts, one which usually forces the data (our numerical representation of text in this case) into a smaller size, and a part on the other end that restores the data back to its original size.
I could write a whole different blog post about autoencoders, but this concept of forcing data into a smaller size and letting the neural network learn what is important to keep track of, is a recurring concept central to many different artificial intelligence algorithms. We even have a fancy term, called “latent space” that you may have heard before, for this part of the model where the data is in a more compressed size.
Here the Anthropic team do something different than your standard autoencoder. Rather than be trained to compress the representation of the data, this Sparse Autoencoder is trained to enlarge it. Lets ignore that first term (sparse) for a little bit, we will come back to it.
The authors at Anthropic have trained an auto encoder that takes the activations (that result from our model combining text and its parameters) and transforms them into many more numbers, and then at the other end of the pipe they can recreate almost exactly the activations.
Here is an example to make things more concrete:
- We take our phrase or sequence of text, and transform it into a numerical representation.
- We pass that representation into our neural network, and throw the kitchen sink of simple mathematical operations at it. In the end we have combined our text and our parameters into a list of numbers, organized into directions of a specific length (i.e. two numbers).
- Some of these lists of numbers are large, and others are small (i.e. close or far from the origin point). We call these numbers our activations.
- This is where we add our sparse autoencoder: the sparse auto encoder takes the activations, expands them to lists of many more numbers, and then is able to recreate the same original activations at the other end, to ensure that we predict the same piece of text in the end.
- After going through the sparse autoencoder, the model should predict exactly the same text as it would have before.
In the middle part of the sparse auto encoder, we have expanded the possible set of features that the model can express. This is basically like saying we have given the model a way bigger dictionary to use for storing information. This type of algorithm is actually called “dictionary learning” for this reason. If our original model was predicting text using lists of two numbers, if we let it use lists of 4 or 12 or 16 numbers, it would have many more options to represent different features.
But why go through all this trouble? Didn’t we just make our lives much more difficult by expanding the range of possible features, when we have been trying to nail down their specific meaning this whole time?
This is where this term sparse comes in. When we use sparse in this context, what we mean is “rarely occurring”. So when the Anthropic authors say that the model has learned “sparse features” they mean that the model has learned features which do not occur often, and thus do not mix together in a very hard to decipher pile.
We gave the model larger lists to use to represent features as directions in higher dimensions, but most of those features will be zeroes, and when its not a zero, we can easily connect that non zero value to a specific concept in our text and identify the meaning of our feature.
In our example of predicting house prices, this is like a house having a rare amenity, like a pool or a jacuzzi or a trebuchet. It happens so rarely that when it does, we can usually identify that the price of the house will be higher, just because of this addition.
The objective of making sparse features is that we can much more easily connect specific behavior of our language model to the activations of specific features. If each feature occurs very rarely, when it does occur, we should be able to find what kind of text it is connected to.
This process of using the auto encoder to learn these sparse features has been demonstrated a few times before. But one new thing the authors did in this paper was demonstrate that it could be done successfully on a really large and useful model like Claude 3 Sonnet. This type of breakthrough in “scalability” is really important.
Interpreting our Sparse Features
So now that we have our much more cleanly separated and identifiable features we can do some really cool stuff. When looking at how the model chose what text to predict next, we previously had a mixture of many different numbers that could all be responsible. But now we have just a few, and we can start to connect these features to specific behavior, like finding the feature for a historical figure or specific emotion.
The team at Anthropic built a lot of advanced user interfaces to help this process and connect the activations in the sparse autoencoder (the feature) to a specific concept in language. Let’s look at an example: the feature which seems to represent the Golden Gate Bridge.

In this image we see lines of text, some of them in different languages. Each line of text is a different input to the model, where the model’s objective is then to predict the text which comes next.
The important parts are the orange highlighted portions. These parts show where this feature (the one that seems to look for the Golden Gate Bridge) has a high activation.
When the text is going through the model, each feature has an opportunity to combine with each part of the text input and produce a corresponding activation. By feeding different text into the model and seeing which parts activate, the authors were able to identify that this feature is strongly connected to the Golden Gate Bridge.
This feature seems to work across languages, and even in pictures. Thus we can conclude that this part of the model “understands” the Golden Gate Bridge, and is useful for identifying and understanding this concept.
The authors find this example by looking at many pieces of text in their dataset, and finding which pieces of text cause this feature to have the highest value.
Another really cool result is found when the authors develop a form of “distance” between features. In English, we might say two words are close to one another when they represent similar concepts, like “cold” and “chilled”. But beyond just synonyms, we could say that terms like “cold” and “snow” are similar, maybe because they occur together often, or because one reminds you of the other.
The paper presents a numerical “distance” which brings features together, and we find that features that are close in this measurement share similar meaning or occurrence.
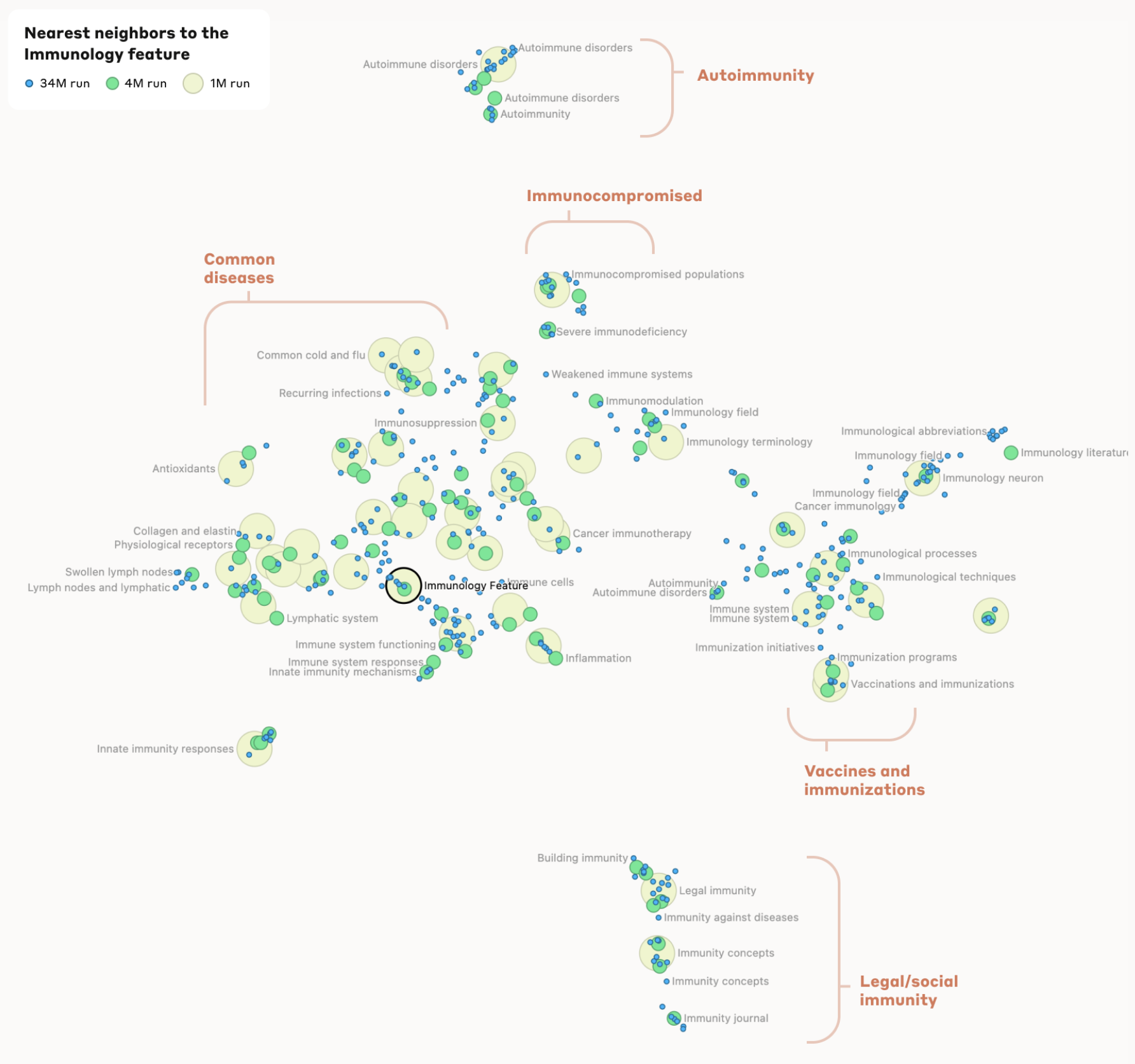
Here we see a map of this distance, for a different feature this time. This feature seems to represent “immunology”, and have a high activation for text having to do with the immune system. Nearby (meaning close in distance) we find common diseases, vaccines, and many concepts we would consider closely related to immunology.
Interestingly enough, a little further away we even see features representing more conceptual immunity, like legal immunity.
The authors can use this method to potentially discover new features inside the language model. They created a handy user interface for browsing these neighborhoods, viewable here.
Browsing through these features, I wanted to point out an example where we can see some of the subjectivity that exists in the labels or meanings applied to these features
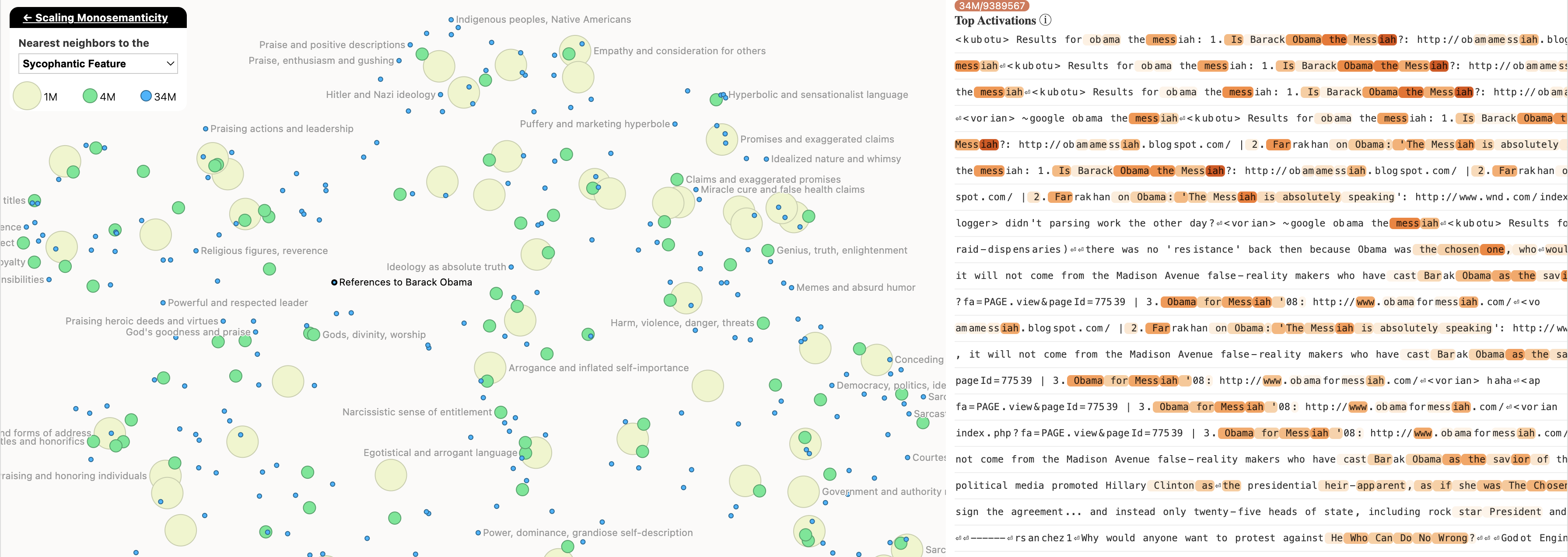
This is the map of the nearest features to the “Sycophantic” feature, which activates when the model sees very emphatic or obsequious text. Here we find a feature labeled “Barack Obama”. However when looking at the text on which this feature has the highest activation, we see repeated examples of “Obama the Messiah”. Rather than being a feature for sycophantic praise of Barack Obama, we might more call this a feature representing messianic references to Barack Obama.
The authors do use more automated methods to find features, such as using their own LLM to help out, but this example highlights that labeling these features is not yet an exact science, and these labels can be somewhat subjective.
In the next section we will see these features used in a way the authors describe as “causal”.
Using Features to Change the Model’s Behavior
Once the features were identified, the authors were able to force the value of a specific feature to have a higher or lower value, and were able to change the output of the LLM. This demonstrates causality, that the feature is the cause of specific behavior.
When we say that the value of a feature is forced to a specific value, we mean when the part of the neural network that corresponds to this feature sees any text, it activates with this specific value rather than what the feature would normally activate with. This results in this feature lending more or less weight towards the predicted text than it naturally would.

The image above is a quite silly example of forcing the “Golden Gate Bridge” feature to have a high activation. We see the model change its response quite drastically, it begins to respond as if it is the Golden Gate Bridge itself.

In this next example, forcing the “Popular Tourist Attraction” feature to have a high activation not only causes the model to recommend the Eiffel Tower, but also to express quite a bit of disappointment at the monument. Despite being named Claude, it seems the LLM isn’t the biggest fan of Paris! Here we can see again that the feature labels are not perfectly specific, and these features can have a surprising effect.
The authors conduct further experiments using the causality of features, such as testing how fixing the value of a feature to zero affects the prediction of text when there is an expected “right” answer. This type of study, called an ablation, allows the authors to find the features which might correspond to the model’s “chain of thought” when predicting the next piece of text.
The paper includes a lot more information and other interesting experiments, but I want to save time for what might be the most significant part of the paper, the safety relevant features.
Accessing Safety Relevant Features
We might want to better understand neural networks and LLMs because they are intrinsically interesting, but we also need to better understand them in order to make them more useful. The Anthropic team makes the argument that making these models more useful means making them more safe. Safety can mean many things, but in the context of this paper the authors identify safety as “mitigating model misuse, preventing biased or hateful output, and reducing the mismatch between model objectives and human values”.
To that end the authors identify several safety relevant features, such as a feature which causes the model to produce unsafe code, features that make the model produce hateful output, and features that cause the model to behave dishonestly. Most of these features cause the model to behave very unsafely when set to a large activation.

The image above shows two very interesting features that when set to a high value affect the transparency of the model’s response. The original prompt has the model playing along and trying to be helpful by pretending that it has forgotten a word. With “Internal Conflict” forced to 2x its maximum, the model admits that it has no ability to forget text it has seen. And likewise when “Honesty” is clamped to 3x its maximum, the model immediately responds with the truth, rather than pretending to have forgotten the word.
I think it is important to quote the caveat given by the authors here: “[I]t’s important to note that the present work does not show that any features are actually useful for safety. Instead, we merely show that there are many which seem plausibly useful for safety”.
This statement implies that these features have been demonstrated to exist, and to be identifiable. But the authors have not demonstrated a system where we could control these features and lead to a statistical reduction in unsafe behavior. This type of evaluation could take many forms, but often in Machine Learning research we speak about benchmarks. These are controlled and public assessments of a model’s performance on a very specific task. For example in the LLM community, a very widespread benchmark is the Measuring Massive Multitask Language Understanding (MMLU) benchmark which consists of multiple choice questions from many different subjects. We compare many models on their performance on this benchmark to say if a model is more or less advanced.
One thing that is missing from the safety relevant feature discussion in the Anthropic paper is a similar benchmark. Perhaps an evaluation where we measure how well we can edit a model’s undesirable output by manipulating the features. Evaluations like this have been done by other authors, and I am sure the Anthropic team will introduce this type of quantitative evaluation, but its important to point out that model safety hasn’t been “solved” yet (and no where do the authors ever claim it has been, to be clear).
Conclusion: Why Pay Attention to Interpretability Research?
In building upon and scaling up their previous work, the Anthropic team were able to identify many unique and specific concepts, called features, in the weights of an LLM. These features correspond to both concrete objects like the word immunology, but also more abstract representations, like different fields within the science of immunology or immunity in a legal or social context.
This type of research allows us to explore more clearly what the large language model has learned. Specifically this type of research could in the future create methods to more specifically control the behavior of the models. We could limit misinformation, increase reliability, and achieve many other positive outcomes.
As we integrate LLMs more and more into our daily lives, being able to control and understand precise behavior of the models will make them more trustworthy and allow us to place more confidence in their responses. I look forward to the future work of the Anthropic team and other interpretability researchers.
I hope to post more educational content about artificial intelligence in the future, so stay tuned!
If you are interested in getting a deeper, mathematical understanding of these systems, here are some links to get you started:
- 3Blue1Brown on YouTube has an excellently made series of videos explaining Neural Networks: link
- Andrej Karpathy is undoubtedly the GOAT (greatest of all time) public educator on artificial intelligence, and his channel is a great resource: link
All images courtesy of the Anthropic team.